Flume 简介
Flume 是一个分布式、高可靠、高可用的用来收集、聚合、转移不同来源的大量日志数据到中央数据仓库的工具.
Flume 还具有强大的流机制, 大多数场景下 Flume 作为数据流的起点, 通过 kafka 等消息队列将数据流原因不断的传输到其他流计算或者 Hdfs, hbase 等存储节点, 用作实时分析计算或者离线数据仓库存储等.
Flume 详解
基本概念
Event直译为事件, 动作, Event 描述一个原子数据单元从输入端到输出端的过程, 但 Event 只是描述了数据流动的事件, 事实上 Event 从输入端流到输出端的事件的全过程是由 Agent 来控制的.Agent直译为代理, Agent 代理了 Event 的行为, Agent就是一个Flume的实例,本质是一个JVM进程,该JVM进程控制Event数据流从外部日志生产者那里传输到目的地(或者是下一个Agent)。
那么 Agent 是怎么控制数据流动的呢? 通过Source, Channel, Sink来控制的. Source 输入数据, Channel 暂存数据, Slink 输出数据
Source. source 用来接收 Event 数据作为 Flume 的输入源, 满足 Thrift协议 的 Event 数据都能被source识别和接收. source 接收到数据后转存到 Channel.Channel. Channel 用来存储 Source 接收到的数据, 直至被 Slink 消费到为止.Slink. Slink用来消费Channel存储的数据, 并将数据输出到消息队列 kafka 或 存储 Hbase, Hdfs, 或 ........
Source 输入数据
Source是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中。
Flume提供了各种source的实现,包括Avro Source、Exce Source、Spooling Directory Source、NetCat Source、Syslog Source、Syslog TCP Source、Syslog UDP Source、HTTP Source、HDFS Source,etc。如果内置的Source无法满足需要, Flume还支持自定义Source。
Channel 数据存储
Channel是连接Source和Sink的组件,大家可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件。
Flume对于 Channel,则提供了Memory Channel、JDBC Chanel、File Channel,etc。
- MemoryChannel可以实现高速的吞吐,但是无法保证数据的完整性。
- MemoryRecoverChannel在官方文档的建议上已经建义使用FileChannel来替换。
- FileChannel保证数据的完整性与一致性。在具体配置不现的FileChannel时,建议FileChannel设置的目录和程序日志文件保存的目录设成不同的磁盘,以便提高效率。
Slink 输出数据
Flume Sink取出Channel中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。
Flume也提供了各种sink的实现,包括HDFS sink、Logger sink、Avro sink、File Roll sink、Null sink、HBase sink,etc。
Flume Sink在设置存储数据时,可以向文件系统中,数据库中,hadoop中储数据,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。
Flume 业务定位
Flume 处于数据链的最顶端, 对接数据产生方, 负责将数据生产方产生的数据(日志, 流水等)以流式实时传递出去.
Hadoop业务的整体开发流程图
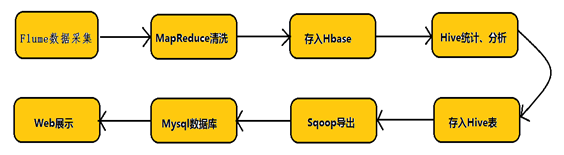
Flume 数据流
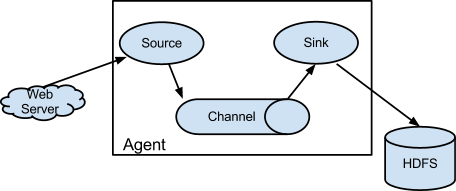
基础流模型
Flume 作为一个流式应用程序, 没有什么比图来的更为直观的了.
下图是 Flume 基础流模型内部数据流转图
数据流转方向WebServer.log->Source->Channel->Slink->HDFS
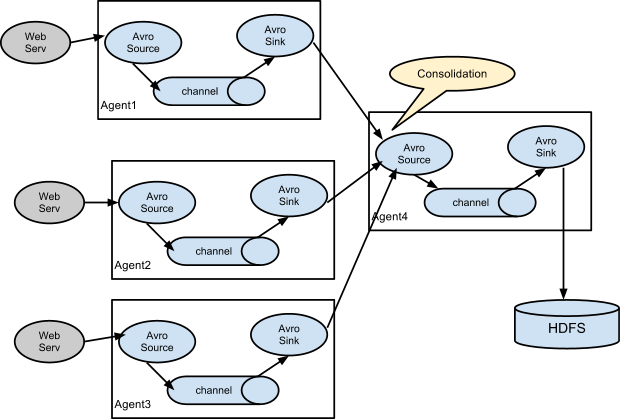
复杂流模型
下图是 Flume 复杂流模型内部数据流转图
这是个分布式数据流采集流程, 每个Web应用程序都绑定了一个 Flume 收集日志, 这些 Flume 把采集到的日志汇总到一个主 Flume. 主 Flume 最终落地到HDFS
Flume 安装
- 下载. https://flume.apache.org/download.html
- 解压
tar zxvf apache-flume-{version}-bin.tar.gz
3.配置 JAVA_HOME
cd apache-flume-1.9.0-bin/conf
cp flume-env.sh.template flume-env.sh
vim flume-env.sh
首行加入export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
4. 测试版本 ./bin/flume-ng version
Flume 1.9.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: d4fcab4f501d41597bc616921329a4339f73585e
Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018
From source with checksum 35db629a3bda49d23e9b3690c80737f9
Flume 配置
具体如何配置 source, channel, sink, 请参考官网, 这里就一一不拷贝了 https://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html
下面简单介绍几个Demo
Flume 实战演练
采集 Nginx 日志并打印到控制台
- 配置
flume-nginx-console.conf
# 名为 nginx 的 Agent, 配置 source, channel, sink
nginx.sources = source
nginx.channels = channel
nginx.sinks = sink
# 配置source
# terminal 读取 access.log
nginx.sources.source.type = exec
nginx.sources.source.command = tail -f /var/log/nginx/access.log
nginx.sources.source.channels = channel
# 配置channel
# 类型 内存channel , 最大容量为1000, 最大事务容量为100
nginx.channels.channel.type = memory
nginx.channels.channel.capacity = 1000
nginx.channels.channel.transactionCapacity = 100
# 配置sink
#输入 channel, 输出类型为logger输出
nginx.sinks.sink.channel = channel
nginx.sinks.sink.type = logger
-
启动
flume-ng
bin/flume-ng agent --conf conf --conf-file conf/flume-nginx-console.conf --name nginx -Dflume.root.logger=INFO,console -
另开一个终端, 执行
curl localhost, 查看 flume 是否打印access日志
采集 Nginx 日志并发送到kafka
- 配置
flume-nginx-kafka.conf
# 名为 nginx 的 Agent, 配置 source, channel, sink
nginx.sources = source
nginx.channels = channel
nginx.sinks = sink
# 配置source
# terminal 读取 access.log
nginx.sources.source.type = exec
nginx.sources.source.command = tail -f /var/log/nginx/access.log
nginx.sources.source.channels = channel
# 配置channel
# 类型 内存channel , 最大容量为1000, 最大事务容量为100
nginx.channels.channel.type = memory
nginx.channels.channel.capacity = 1000
nginx.channels.channel.transactionCapacity = 100
# 配置sink
#输入 channel, 输出类型为kafka
nginx.sinks.sink.channel = channel
nginx.sinks.sink.type = org.apache.flume.sink.kafka.KafkaSink
nginx.sinks.sink.kafka.topic = nginx
nginx.sinks.sink.kafka.bootstrap.servers = localhost:9092
nginx.sinks.sink.kafka.flumeBatchSize = 20
nginx.sinks.sink.kafka.producer.acks = 1
nginx.sinks.sink.kafka.producer.linger.ms = 1
nginx.sinks.sink.kafka.producer.compression.type = snappy
- 启动
flume-ng
bin/flume-ng agent --conf conf --conf-file conf/flume-nginx-console.conf --name nginx -Dflume.root.logger=INFO,console - 另开一个终端, 执行
curl localhost, 查看 kafka 是否收集到access日志